
Quick Reference
Cluster Machine List and Queue overview
Click here for a list of names and specs for each of the nodes in the cluster along with an overview of the queues that you can submit jobs to.
View the current cluster usage (On Campus or VPN connection required)
See here for visual graphs on the current usage. This is an outside link to the ganglia page for the current cluster.
Getting Access and Eligibility.
All College of Engineering students are pre-approved for access to the cluster. Contact us and we will add you to our cluster users group, allowing access to the cluster.
Faculty and staff members must own at least one node to gain long-term access to the Asha cluster. Please contact us for more info.
General Guidelines
- Move your data to your scratch folder prior to running your job.
- /home/ is not mounted on the compute nodes and any reference to it may prevent your job from running successfully.
- /scratch/your_user_name (e.g. /scratch/joeblow) is your working directory for all jobs. It is symbolically linked in your home directory as “scratch”, but do not reference items through that symbolic link. For example use “/scratch/your_user_name” to reference files/data instead of “/home/your_user_name/scratch”
- Your job will fail if you do not move your data or reference settings/files in your home folder.
- Use the job scheduler.
- Do not run jobs on the login node. Processes that impact the performance of the login node will be killed without notice. If you need help running your job, please contact us and we can sit down and walk you through it.
- Be good to each other.
- This cluster is shared by all in the College of Engineering. Please do your best to be fair and kind to others.
Running a Job On the Cluster
The normal job flow with working with the cluster usually goes as such.
- Move your data and code to the cluster and place it in your “scratch” folder.
- For Linux and OSX users, we recommend scp or sftp.
- For Windows, Filezilla is widely used.
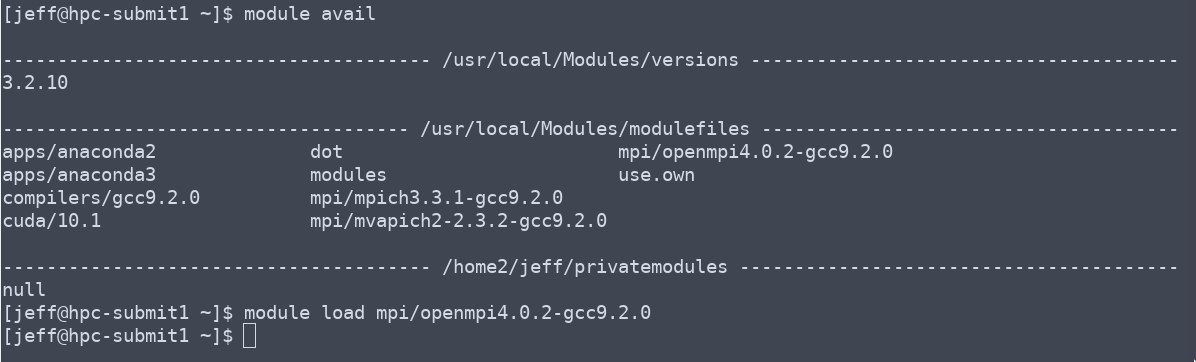
- Load any modules, or set any environment variables that are required. More info.
- Write a submission script with your options and execution instructions. More info
- Submit your job to the cluster with the “sbatch” command.
- For info on how to submit, watch, cancel, or find info on your job please see the basic usage guide.
- When your job is done, gather any outputs you would like saved and move them back to /home for long term storage.
Example Workflow
From your client machine, upload your data and connect to the cluster.

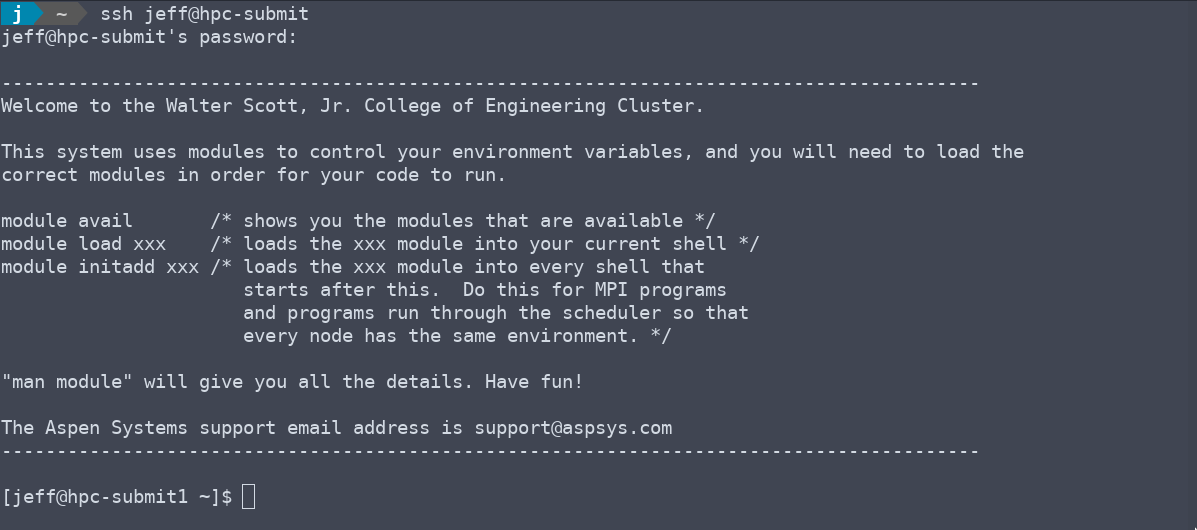
Load any needed modules.
Move to the scratch space and write your submission script.


Submit your job. When it is done, check your data and output file for errors or standard output.
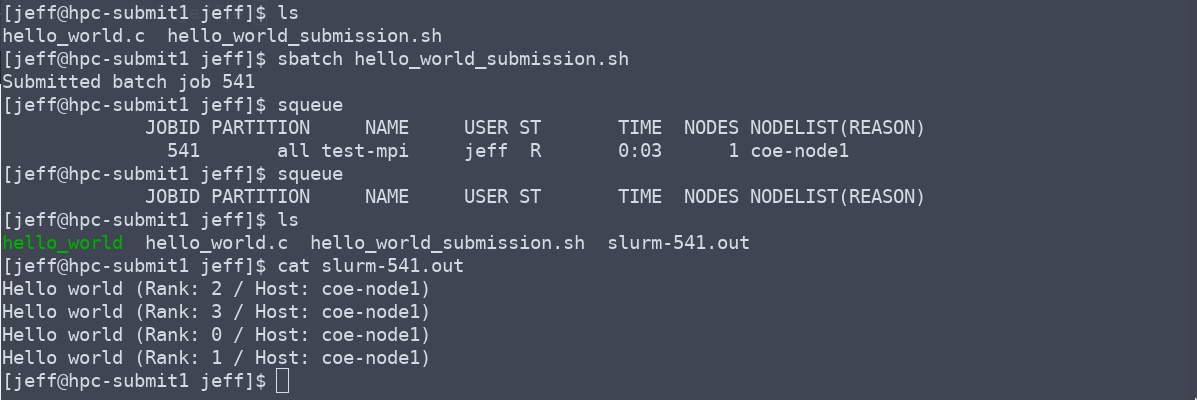
Move your data back to your home directory.

Partitions
Partitions are a group of machines on the cluster that can define limits and priority. These partitions can contain overlapping groups of nodes. When you submit your job, resources are allocated from the partition you define, and your job runs on one or all of the nodes in that group. You can use the command “sinfo” to see the list of partitions you can submit to. Below are a list of basic partitions configured on the Asha cluster.
- coe-cpu
- All College of Engineering general compute student CPU cores
- Note: coe-cpu is the default partition.
- coe-all
- All College of Engineering general compute student nodes (CPU and GPU).
- all
- All nodes in the cluster
- Note: Jobs submitted to individual research group’s partition will override this partition. This stops your job completely and places it back into the queue.
- Use these queues for multiple short term jobs or jobs that are not high priority.
- Use the “–nodelist” and “–exclude” options to run your jobs on subsets of the the all partition.
- Research group or Department partitions.
- If your research group or department has purchased a node on the cluster they will get a priority partition for their nodes. These partitions override the “all” queues.
See here for the current node list.
Storage on the Cluster
Each user gets 500GB of space in /home and 1TB in /scratch by default.
Please contact us to purchase more individual space, or get shared space for your project group.
Useful Links
Scheduler Help
- Stanford’s SGE to Slurm Transition Guide (For transitioning your scripts from the Keck Cluster to the Asha Cluster)
- Slurm Getting Started Guide
- Slurm Tutorials (video series and other resources)