Scenario
|
Description
(grid size, temporal resolution)
M=1 --> every sample is saved
M=2 --> every 2nd sample is saved
M=4 --> every 4th sample is saved
etc.
|
Scenario name (XXX)
|
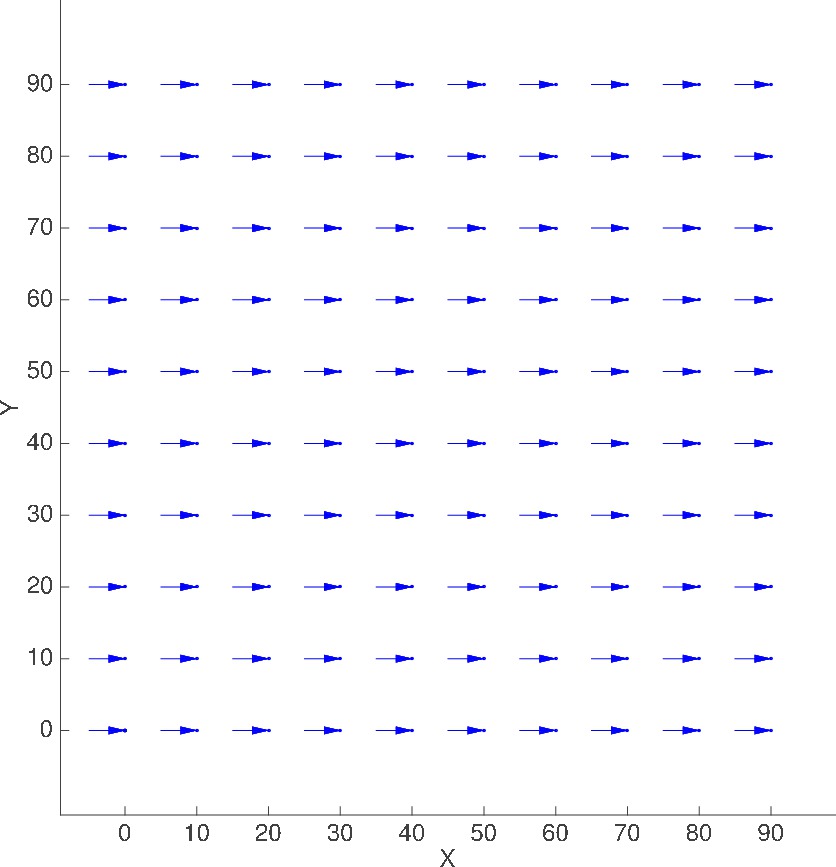
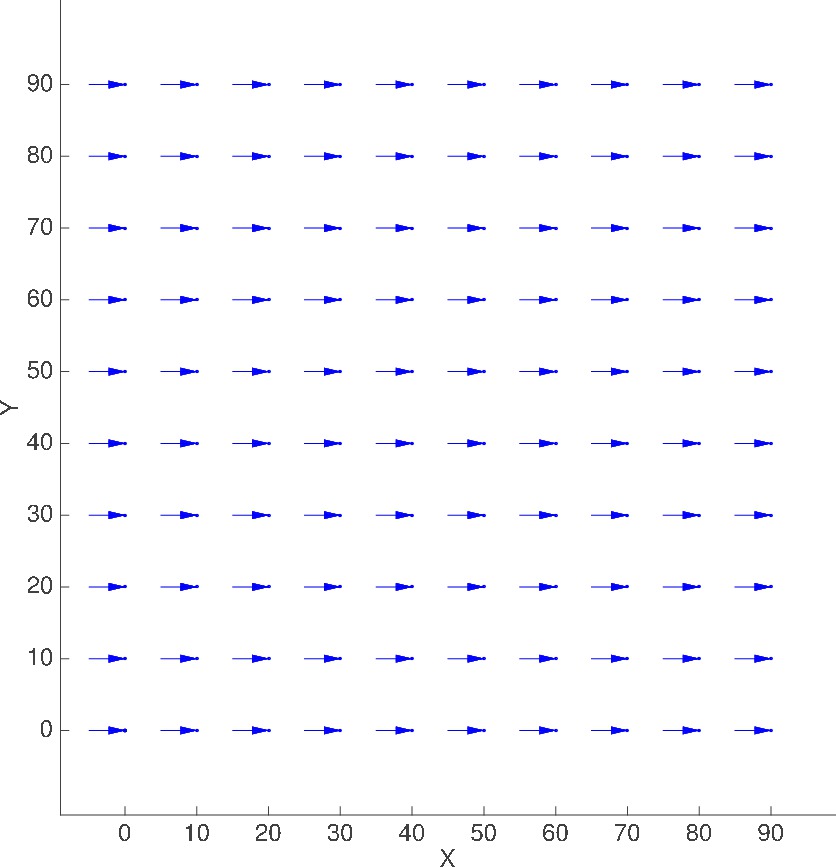
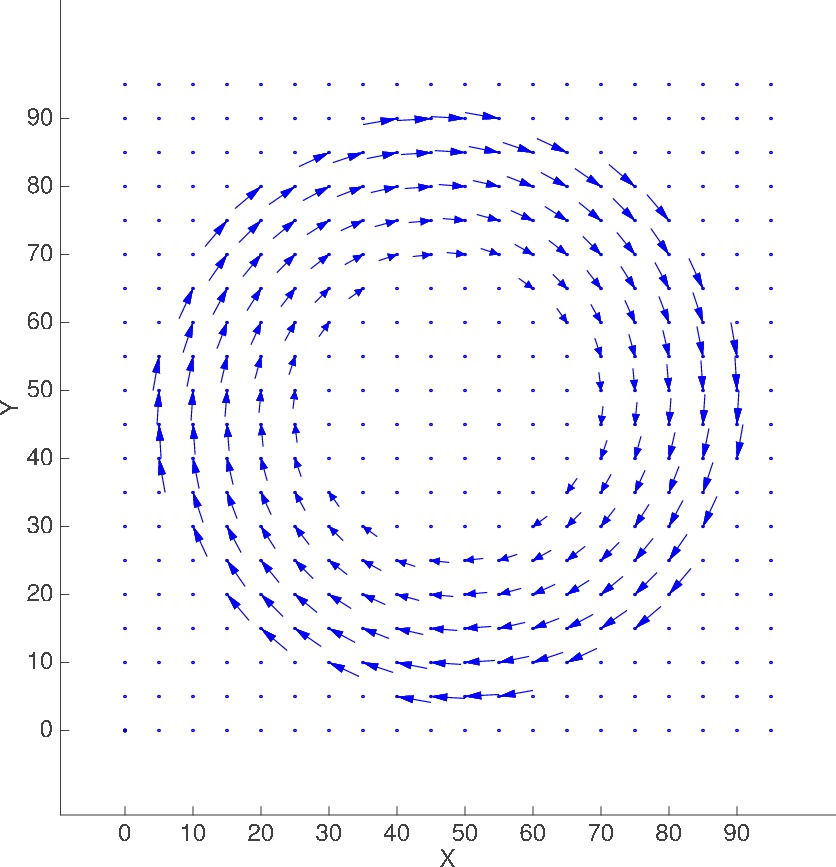
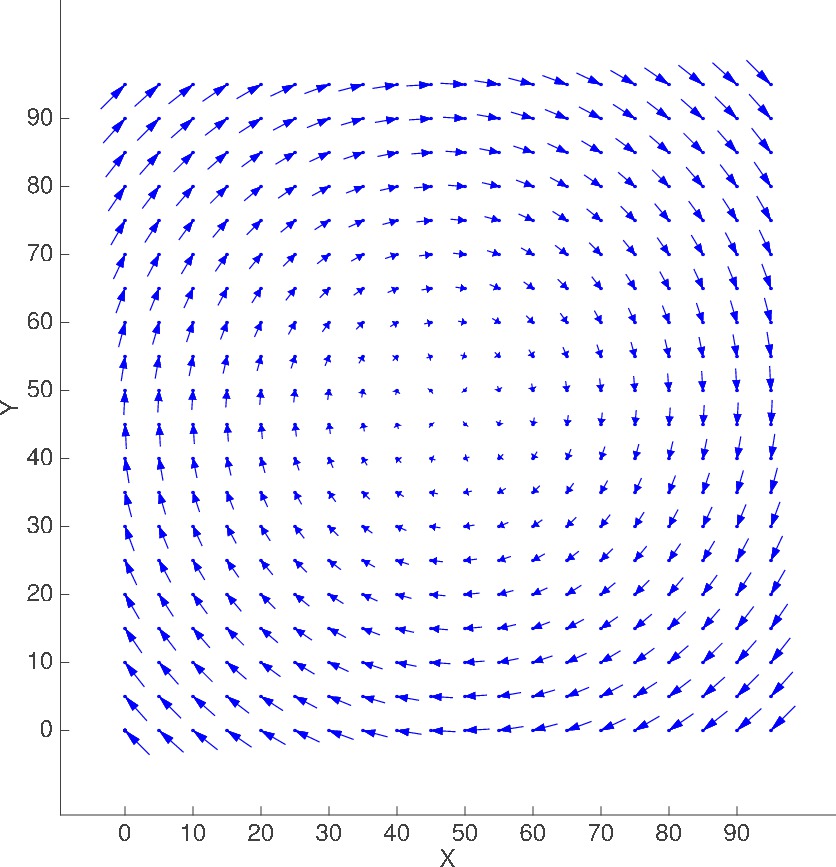
Plot of Advection velocity field
(displacement shown is in meters for t = 5 sec)
|
A) SIMPLE SCENARIOS
|
|
|
|
Pure Advection
|
|
|
|
|
10x10 grid, M=1
|
ADVECTION_ONLY_EXP_1 |
 |
|
10x10, M=2
|
ADVECTION_ONLY_EXP_2 |
same as above |
|
10x10, M=4
|
ADVECTION_ONLY_EXP_3 |
same as above |
|
10x10, M=8
|
ADVECTION_ONLY_EXP_4 |
same as above |
|
10x10, M=12
|
ADVECTION_ONLY_EXP_5 |
same as above |
|
10x10, M=16 |
ADVECTION_ONLY_EXP_6 |
same as above |
|
10x10, M=20 |
ADVECTION_ONLY_EXP_7 |
same as above |
|
10x10, M=21 |
ADVECTION_ONLY_EXP_8 |
same as above |
|
|
|
|
|
10x10, M=1, single-point noise
|
ADVECTION_ONLY_INPUT_EFFECT_EXP_1 |
same as above |
|
10x10, M=1, all-point noise
|
ADVECTION_ONLY_INPUT_EFFECT_EXP_2 |
same as above |
|
|
|
|
Pure Diffusion
|
|
|
|
|
10x10, M=1 |
DIFFUSION_ONLY_EXP_1 |
No advection field |
|
10x10, M=2 |
DIFFUSION_ONLY_EXP_2 |
No advection field |
|
10x10, M=4 |
DIFFUSION_ONLY_EXP_3 |
No advection field |
|
20x20, M=1 |
DIFFUSION_ONLY_EXP_4 |
No advection field |
|
20x20, M=2
|
DIFFUSION_ONLY_EXP_5 |
No advection field |
|
20x20, M=4
|
DIFFUSION_ONLY_EXP_6 |
No advection field |
|
10x10, M=1, kx=1, ky=0
|
DIFFUSION_ONLY_EXP_7 |
No advection field |
|
20x20, M=1, kx=1, ky=0
|
DIFFUSION_ONLY_EXP_8 |
No advection field |
|
|
|
|
|
10x10, M=1, single-point noise |
DIFFUSION_ONLY_INPUT_EFFECT_EXP_1 |
No advection field |
|
10x10, M=1, all-point noise |
DIFFUSION_ONLY_INPUT_EFFECT_EXP_2 |
No advection field |
|
|
|
|
Advection and Diffusion
|
|
|
|
|
10x10, M=1, Straight advection field
|
ADV_AND_DIFF_STRAIGHT
|
|
B) COMPLEX SCENARIOS
(complex 2D advection fields)
|
|
|
|
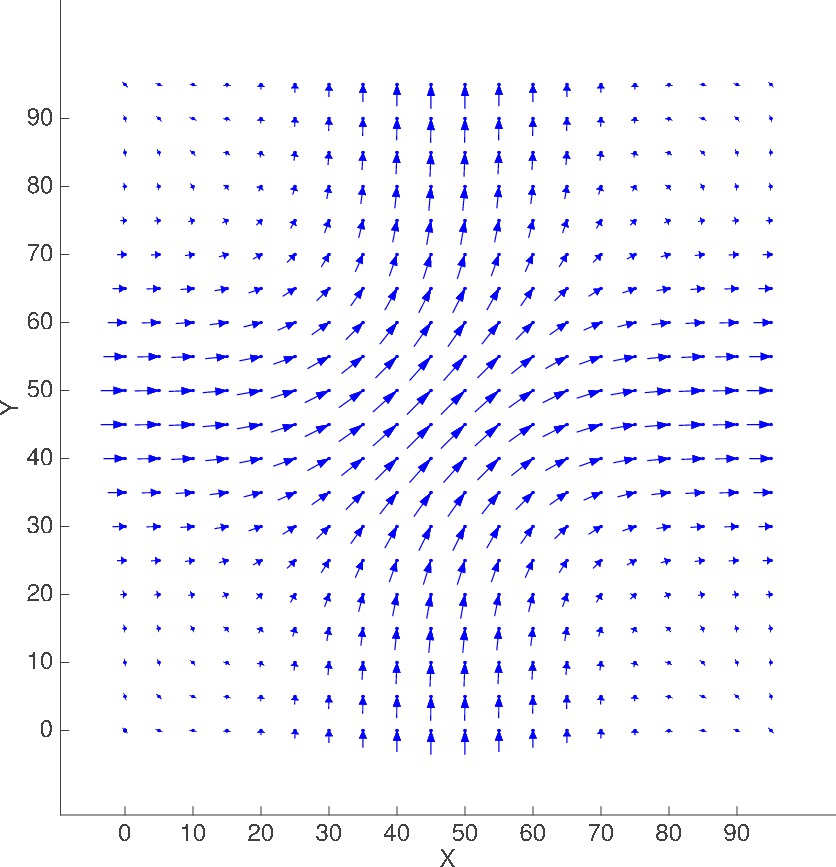
Scenario #1
|
Ring-shaped advection
20x20, M=1
|
ADV_AND_DIFF_CIRCULAR_30_65 |
|
|
Ring-shaped advection
20x20, M=4
|
ADV_AND_DIFF_CIRCULAR_30_65_M_4
|
same as above |
|
Ring-shaped advection
20x20, M=10
|
ADV_AND_DIFF_CIRCULAR_30_65_M_10
|
same as above |
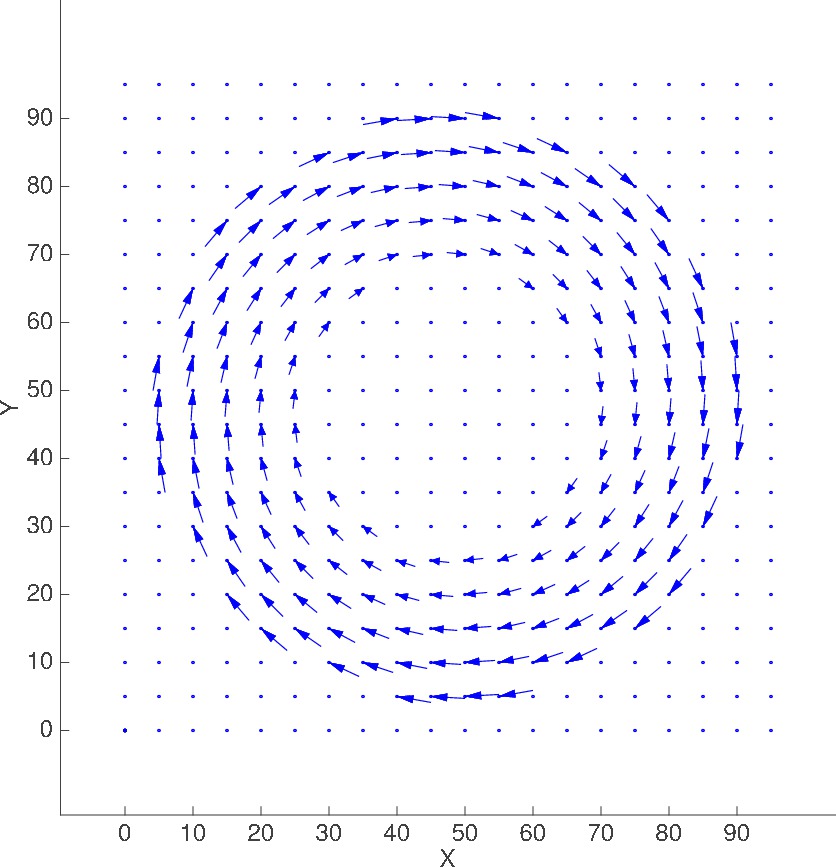
Scenario #2
|
Circular advection
with opposing velocities at boundary
20x20, M=1 |
ADV_AND_DIFF_CIRCULAR_0_100
|
|
Scenario #3
|
Cross current advection,
ywo straight currents crossing each other
20x20, M= |
ADV_AND_DIFF_CROSS_CURRENT
|
|
{kind=link}